The Problem
Idea-Hunt.com(as an AI side project of FeatBit) is a platform that enables SMBs to find the most relevant posts for their services on Reddit in real-time. This allows them to leave high-quality, problem-solving comments, driving more traffic and attracting more customers.
The relevance score is determined by the questions asked by the user in Idea-Hunt. A user can write multiple questions, as shown in the example below, where questions are used to match a Reddit post with a service. These questions are referred to as "evaluation rules."
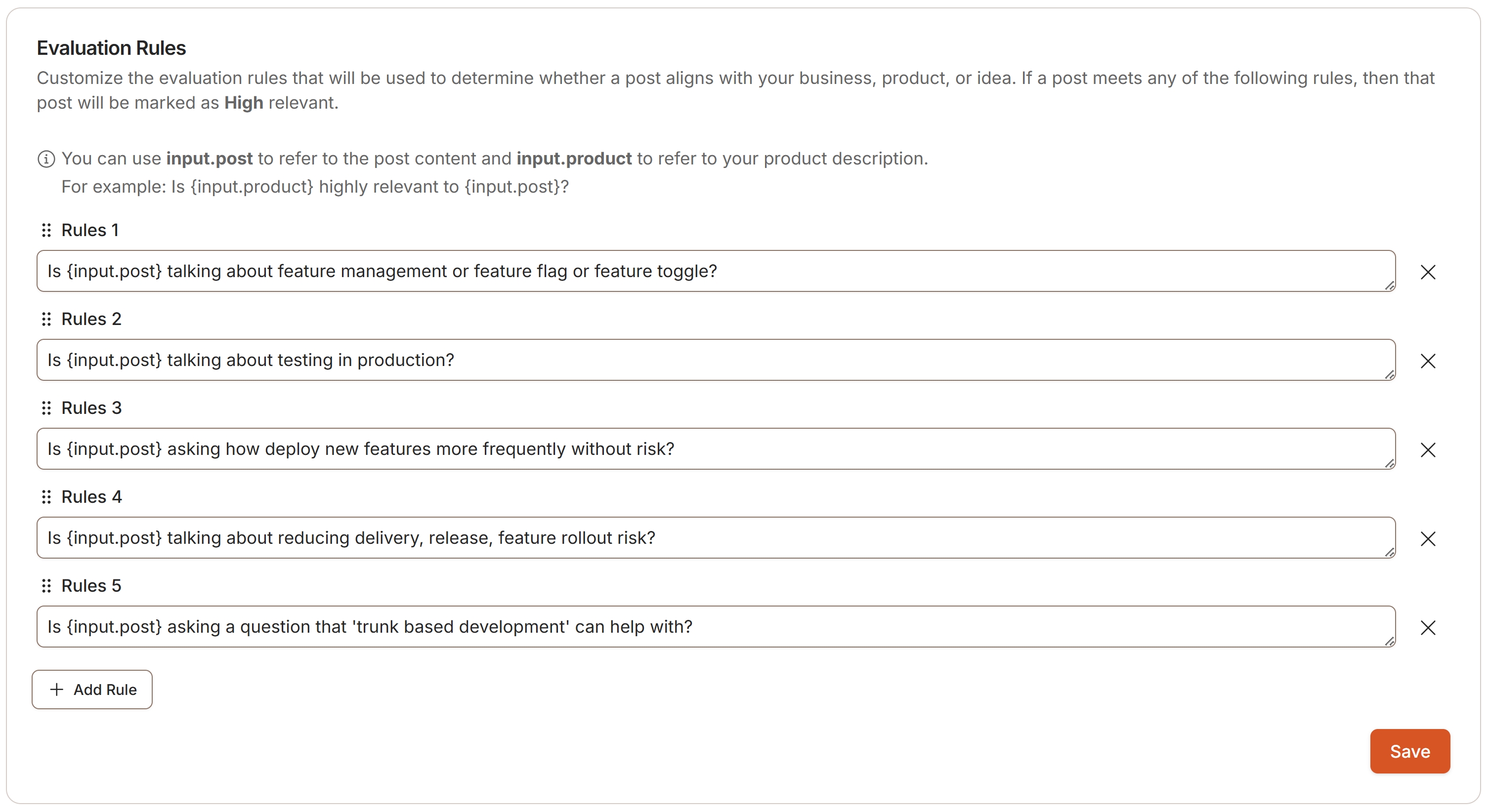
In addition to the user-defined questions, the system also includes a set of predefined rules to evaluate the relevance between a Reddit post and a service. These are referred to as "built-in evaluation rules," as illustrated below:
[
"Does the {input.post} explicitly ask for help, and is the mentioned {input.product} a highly suitable solution for solving the problem?",
"Does the {input.post} describe an issue, and is the mentioned {input.product} an essential tool for resolving this issue?"
]The first scoring strategy works as follows: if any of the questions in the "evaluation rules" are answered with "Yes," the final relevance score is marked as "HIGH_RELEVANT." Only posts marked as "HIGH_RELEVANT" will trigger alerts for users.
However, even when users define highly accurate evaluation rules, the system occasionally alerts users to irrelevant posts (posts that are not truly highly relevant to the user's service). To address this, the Idea-Hunt team aims to improve the accuracy of the relevance scoring by testing a second scoring strategy while retaining the same set of user-defined "evaluation rules."
Attempting a New Scoring Strategy
In the first attemp prompt strategy, the evaluation process doesn't count built-in rules as part of the evaluation. The system only considers the user-defined rules. The second scoring strategy, however, will incorporate both the user-defined and built-in rules in the evaluation process.
If and only if one of the user-defined rules is marked as "HIGH_RELEVANT" and at least one of the built-in rules is marked as "HIGH_RELEVANT," the final relevance score will be marked as "HIGH_RELEVANT".
Prompt Testing Online
The second strategy is uncertain and needs to be tested. Unlike traditional computer programs, AI prompts must be evaluated in real-world scenarios using real data. This is where the Idea-Hunt team is seeking support.
They need to test two strategy prompts online, meaning both in a production environment and with real user cases. If you're familiar with traditional software engineering, this is similar to A/B testing or a Canary Release, which can be managed through controlled releases using Feature Flag technology.
Using FeatBit (an open-source feature flag platform), this can be achieved by creating a multi-variant feature flag. As shown in the image below, a two-variant feature flag represents two versions of the scoring strategy:
- V1 strategy: User-defined evaluation rules only.
- V2 strategy: User-defined && built-in evaluation rules.
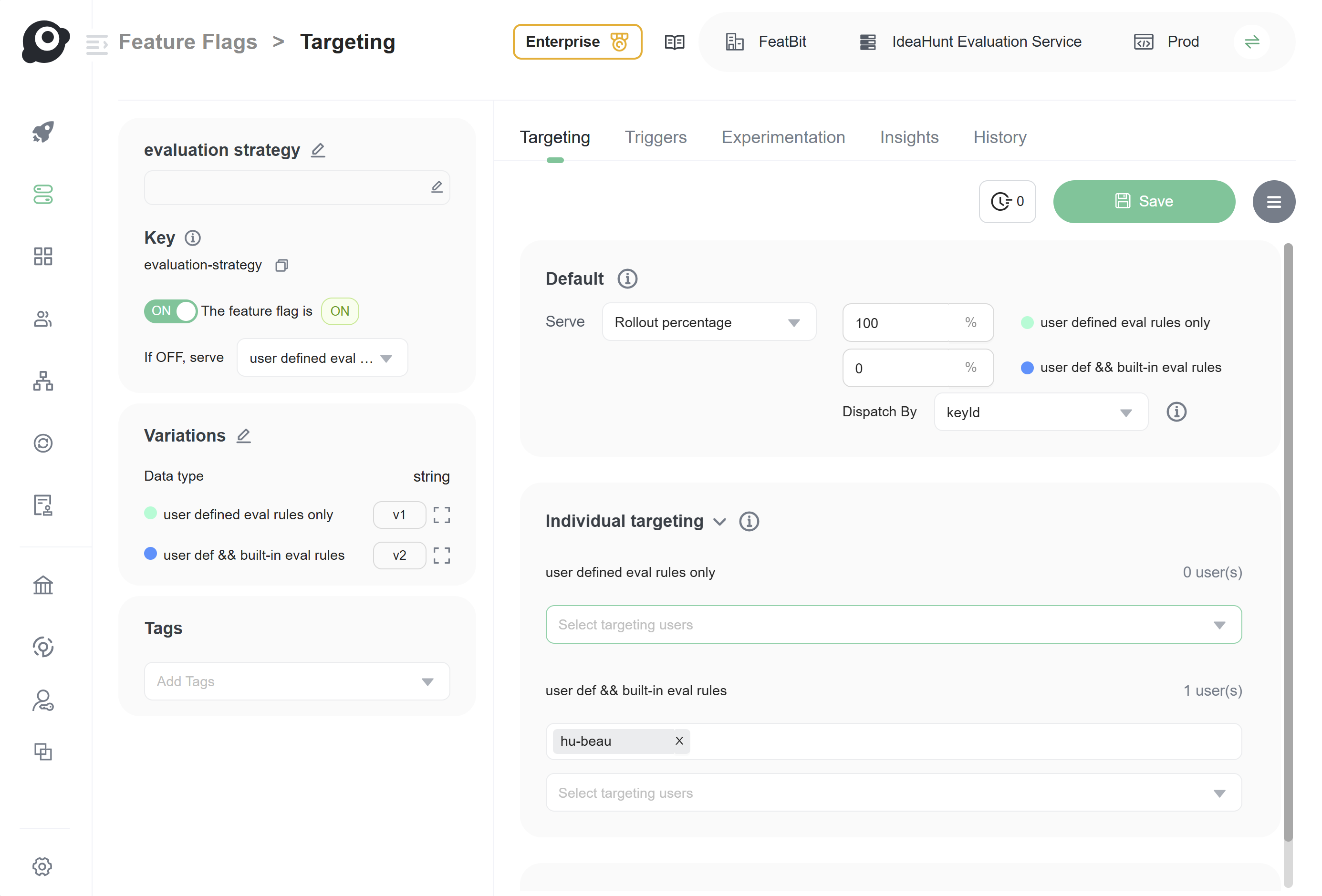
At the start of prompt testing, you can set 100% of users to adopt the first strategy. Then, add an internal team to test the second strategy. As shown above, the user "hu-beau" has been added as the first tester.
Once the internal team has tested the second strategy, you can assign the new strategy to some "deep-connection users." These users are more likely to provide valuable feedback and tolerate potential issues.
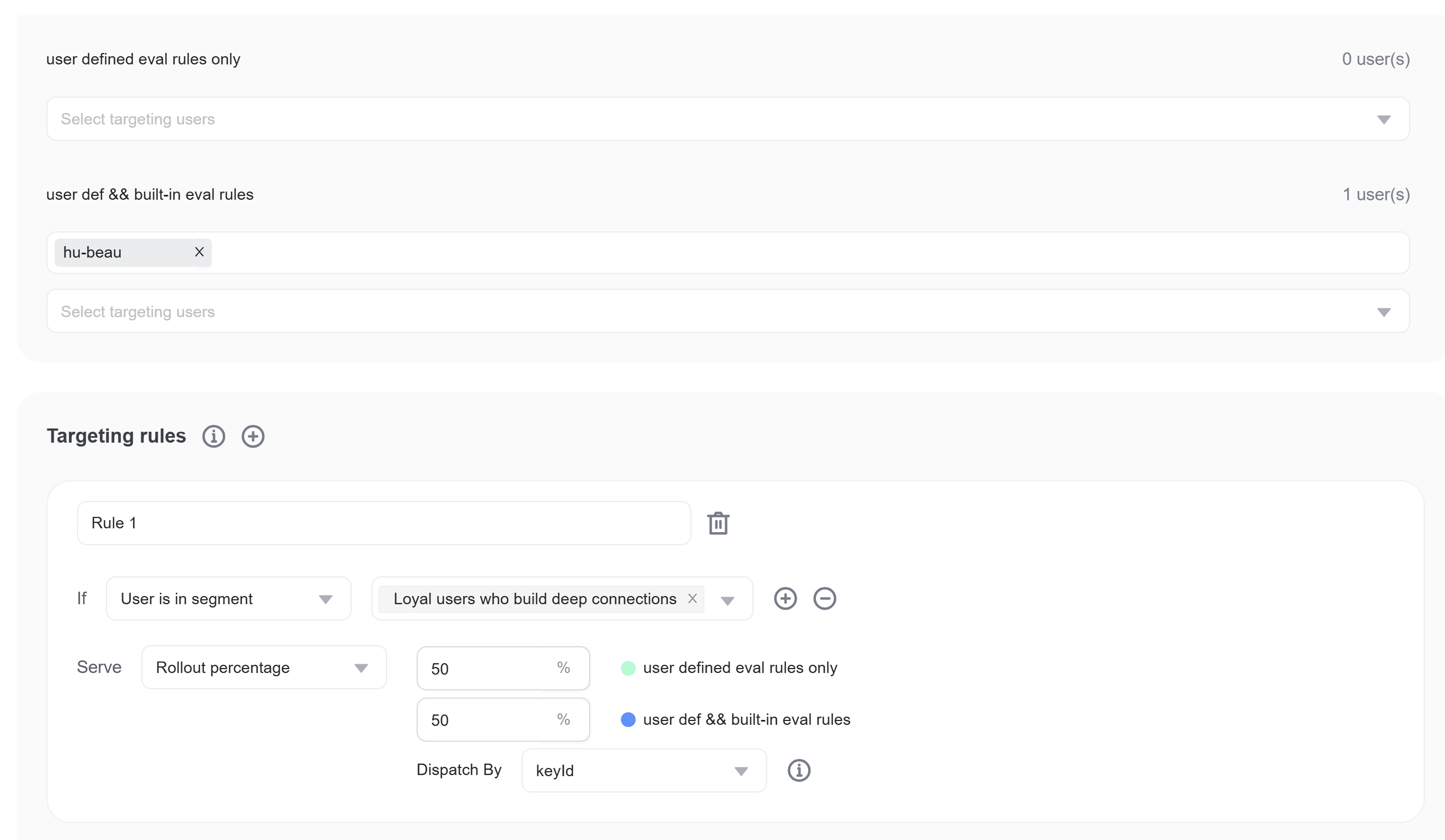
Code to Control Prompt Testing
Below is a snippet of code that uses a feature flag to control the two different scoring strategies:
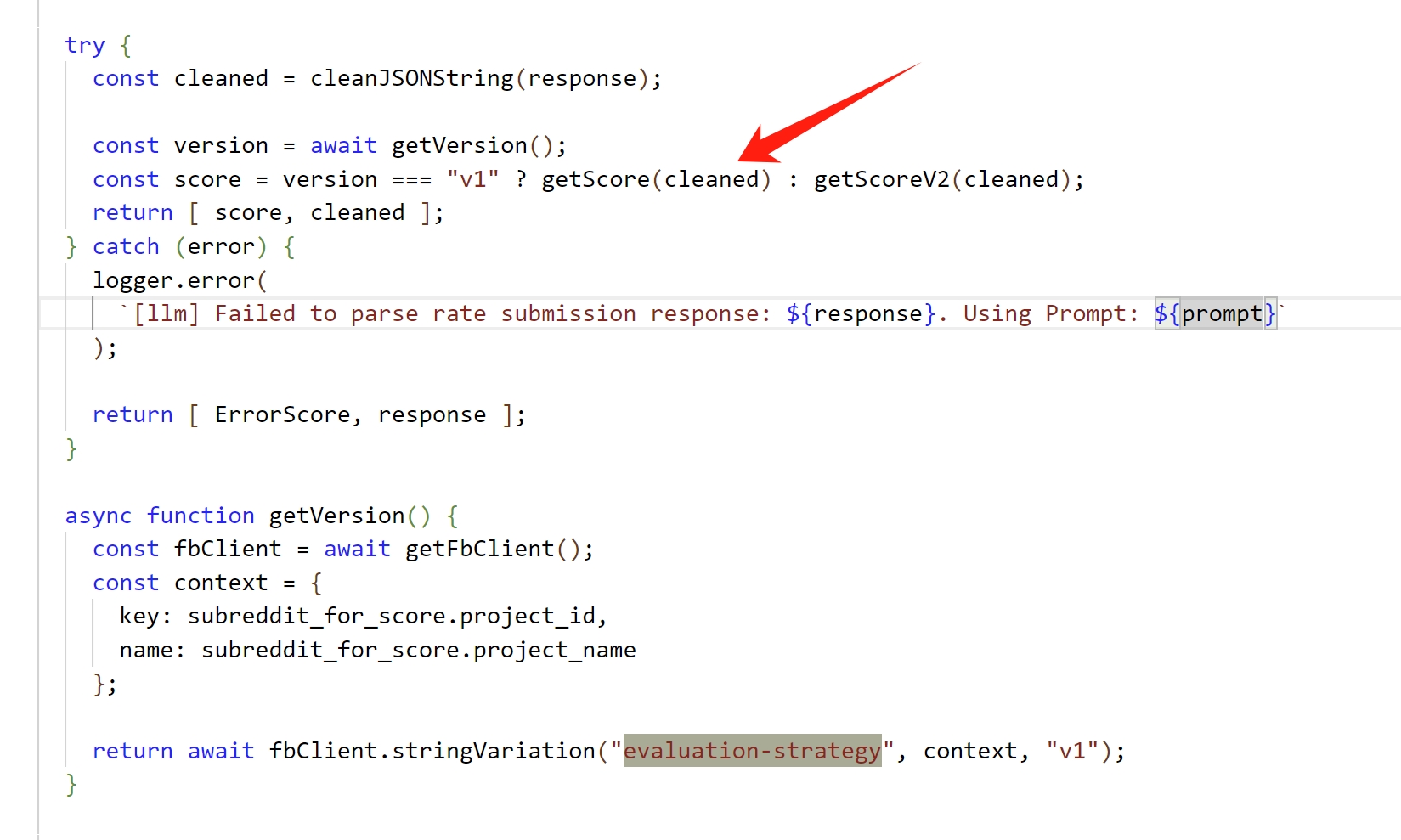
The code await fbClient.stringVariation("evaluation-strategy", context, "v1") retrieves the evaluation strategy from the feature flag. Its return value (either "v1" or "v2") is determined by the user profile context passed to the fbClient.stringVariation function.
Whether you call it A/B testing, a canary release, or a feature flag, the key is to control the prompt testing online and evaluate the new scoring strategy's performance in a real-world scenario.
Feedback & Evaluation
We made thumbup and thumbdown mechanic to collect feedback: if the result is good.
To measure the performance of different prompt strategies (versions), you may say we can use Frequentist or Bayesian statistics to see which version is significantly better.
Yes, it's a good idea, and we truly practice it. But you can't awalys use real-world data to evaluate the performance of the prompt strategy if we continue to improve the accurate or users themselve to continuely improve their prompt.
Fortunately, thanks to librai tech team, we find another way to evaluate the performance of the prompt strategy with less time consuming and help us even end users to evaluate then improve the performace of their prompt in almost "real-time" feedback.
We've implemented a thumbs-up and thumbs-down mechanism to gather feedback on whether the output is satisfactory. To measure the performance of different prompt strategies, one could use Frequentist or Bayesian statistics to determine which version is significantly better.
While this is an excellent approach, it's not always feasible to rely on real-world data if we continuously refine accuracy or if users themselves keep improving their prompts.
Fortunately, thanks to the librai tech team, we've discovered a more efficient way to evaluate prompt strategies. This method allows both developers and end users to assess and enhance prompt performance in near real-time with minimal effort.
We could create our own prompt evaluation system using an evaluator tool with the data we've collected:
- Collect feedback from users, as we did above.
- Use this feedback to train an evaluator prompt that will assess the performance of different prompt strategies.
- The evaluator prompt will not only evaluate the performance of the prompt strategy but also suggest ways to improve the end user's prompt.
This method is still in the experimental phase, but it shows great promise. I'll share more details in the future.